初识JanusGraph
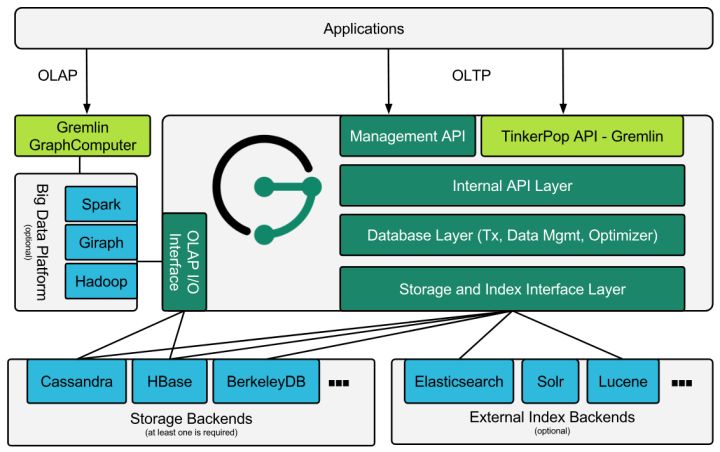
Apache TinkerPop是一款开源的图计算框架,提供图数据库(OLTP)和图分析系统(OLAP)的能力。 图(Graph)是TinkerPop最基本的数据结构,图由顶点(Vertices)和边(Edges)构成,顶点和边都可以有任意数量的由key-value对表示的属性(Properties)。支持Apache TinkerPop的系统可以直接使用Gremlin graph traversal language。
存储后端
- Apache Cassandra
- Apache HBase
- Google Cloud Bigtable
- Oracle BerkeleyDB
索引后端
- ES
- Apache Solr
- Apache Lucene
基于TinkerPop
- Gremlin 图查询语言
- Gremlin 图服务器
- Gremlin 应用
大数据分析
- Apache Spark
- Apache Giraph
- Apache Hadoop
可视化工具
- Cytoscape
- Cephi plugin for Apache TinkerPop
- Graphexp
- KeyLines by Cambridge Intelligence
- Linkurious
索引
图索引(Graph Index)
支持过滤索引,仅在满足特定条件的边或顶点建立索引。包括复合索引和混合索引。
复合索引(Composite Index)
只能进行等值的,包括所有索引键的查询。非等的、只包含部分索引键的查询无法走复合索引。不依赖索引后端,仅依赖存储后端。
混合索引(Mixed Index)
依赖索引后端,提供比复合索引更大的灵活性。支持全文索引、地理位置索引、范围查询。
顶点为中心的索引(Vertex-centric Indexes)
局部索引,只为与顶点相连的某类边建立索引,仅支持等值、范围、包含类查询。
JanusGraph 基本优势
- 支持非常大的图。JanusGraph通过添加机器横向扩展集群。
- 支持很大的并发事务处理和图操作处理。通过添加机器横向扩展JanusGraph的事务处理能力,可以在毫秒级别相应大图的复杂查询。
- 支持使用Hadoop框架进行全局图分析和批量图处理。
- 支持在很大的图上对顶点和边进行地理位置、数值范围、全文搜索。
- 原生支持Apache TinkerPop 描述的当前流行的属性图数据模型。
- 原生支持图遍历语言Gremlin。
- 通过使用非编程的方式连接很容易与Gremlin Server集成
- 提供了很多图级别配置选项用于调节性能。
- 以顶点为中心的索引提供顶点级查询,以缓解臭名昭着的超级节点问题。
- 提供优化的磁盘表示,从而允许有效地使用存储和访问速度。
- 基于 Apache 2 许可协议开放源码。
JanusGraph 使用 Apache Cassandra的优势
- 连续可用,没有单点故障。
- 由于没有主/从架构,因此对图的读/写没有瓶颈。
- 弹性可扩展性允许加入和移除机器。
- 缓存层确保内存中多次连续访问的数据可用。
- 通过添加集群的机器来增加缓存的大小。
- 可以与 Apache Hadoop集成。
- 基于 Apache 2 许可协议开放源码。
JanusGraph 使用 HBase的优势
- 与Apache Hadoop生态系统紧密集成。
- 原生支持强一致性。
- 通过添加更多机器进行线性扩展。
- 严格的一致性读写操作。
- 方便的基类用于支持Hadoop MapReduce作业操作HBase表。
- 支持使用JMX导出监控指标。
- 基于 Apache 2 许可协议开放源码。
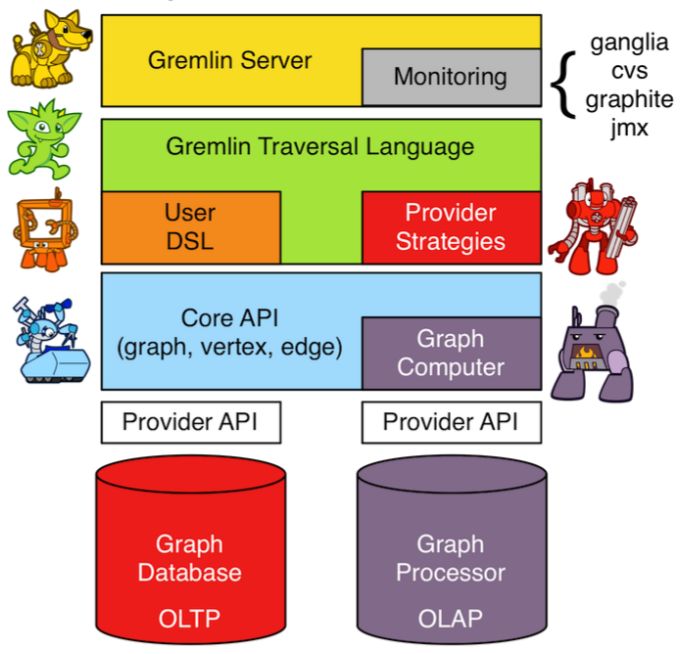
图计算
OLTP
real-time, limited data accessed, random data access, sequential processing, querying
OLAP
long running, entire data set accessed, sequential data access, parallel processing, batch processing
可视化
Gephi
问题
the traversal source [g] for alias [g] is not configured on the server.
在janusgraph--.properties文件末尾加上 gremlin.graph=org.janusgraph.core.JanusGraphFactory 然后重启 gremlin-server
记得启动Cassandra和ES服务
添加/删除 property 不生效
需要在query后面添加 terminal step, 如 next, iterate, tolist等
java.lang.NoSuchMethodError: net.jpountz.lz4.LZ4BlockInputStream.(Ljava/io/InputStream;Z)V
把jar包里的lz4-1.3.0.jar替换为lz4-java-1.4.0.jar
插入边的时候java.util.NoSuchElement
一条边要同时保存在两个顶点的StarGraph里
spark-yarn: can’t parse master url ‘yarn’
下载spark-yarn_x.x-y.y.jar包放在janusgraph/lib目录下
spark-yarn: java.lang.NoSuchMethodError: org.apache.spark.rpc.RpcEndpoint.$init$(Lorg/apache/spark/rpc/RpcEndpoint;)V
saprk_yarn x.x要与janusgraph/lib下的spark-zzz_x.x一致
java.util.concurrent.ExecutionException: java.lang.IllegalStateException: Library directory does not exist; make sure Spark is built.
spark配置里增加 spark.yarn.jars 一项,与 /etc/spark/conf
Error: Could not find or load main class org.apache.spark.deploy.yarn.ExecutorLauncher
使用spark lib下的spark-yarn_x.x.jar
javax.servlet.UnavailableException: Class loading error for holder org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter-d1868cd
cp hadoop-yarn-server-web-proxy-3.0.0-cdh6.2.0.jar
‘org/apache/hadoop/fs/ContentSummary’ (current frame, stack[0]) is not assignable to ‘org/apache/hadoop/fs/QuotaUsage’ (from method signature)
hbase-shaded-client-2.1.2.jar集成了hadoop-common-2.7.7.jar,和hadoop-common-3.0.0.jar有冲突,删掉即可